|
 |
|
|
Geometrical design rules, or just design rules as they are known more commonly, are layout restrictions that ensure that the manufactured circuit will connect as desired with no short-circuits or open paths. The rules are based on known parameters of the manufacturing process, to ensure a margin of safety and to allow for process errors. For example, some nMOS processes require metal wires to be no less than 6 microns wide, as narrower wires could break when manufactured, leaving an open circuit. Similarly, the minimum distance between two metal wires is 6 microns, to prevent fabrication inaccuracies from causing the wires to touch. In some processes the design rules are very complex, involving combinations of layers in specific configurations. Design-rule checking (DRC) is the process of checking these dimensions.
Recently, it was proposed that all design rules could be simplified so that
checking would be easier, and uniform scaling of layout would work
[Mead and Conway].
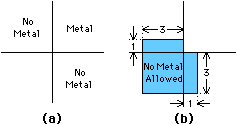
Rather than design rules being specified in absolute distances such as microns,
they would be given in terms of a relative and scalable unit called
lambda (![]() ).
For nMOS design, a metal wire must be 3
).
For nMOS design, a metal wire must be 3![]() wide, and unconnected wires
must be kept 3
wide, and unconnected wires
must be kept 3![]() apart.
When
apart.
When ![]() is 2 microns, this is equivalent to the previous rule.
Since integer multiples of
is 2 microns, this is equivalent to the previous rule.
Since integer multiples of ![]() are easiest to use [Lyon], many real
design-rule sets are approximated when converted to
are easiest to use [Lyon], many real
design-rule sets are approximated when converted to ![]() rules.
The advantage of this relaxation of the rules is that, when process
fabrication allows smaller geometries, the design can easily scale
simply by changing the value of
rules.
The advantage of this relaxation of the rules is that, when process
fabrication allows smaller geometries, the design can easily scale
simply by changing the value of ![]() .
Although layer sizes do not actually scale linearly, the design rules contain
tolerances to allow for many scales.
This is because the rules are based on practical relationships
between process layers that hold true at most scales.
.
Although layer sizes do not actually scale linearly, the design rules contain
tolerances to allow for many scales.
This is because the rules are based on practical relationships
between process layers that hold true at most scales.
The earliest attempts at design-rule checking were based on an algebra of polygons [Baird; Crawford]. This algebra consists of polygon-size adjustment and set operations on the polygon boundaries. For example, the six operations merge, bloat, and, or, xor, and touch can be used to find design-rule violations [Crawford]. Merging combines overlapping polygons on the same layer into one that contains the union of their areas. Bloating expands all polygons on a layer by a specified distance from their center. And, or, and xor are interlayer operations that find the intersection, union, and exclusive areas of two different layers and produce resulting polygons on a third layer. Touch finds all polygons on one layer that adjoin or intersect polygons on another layer.
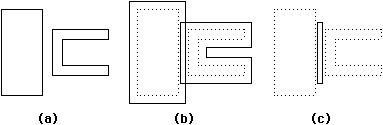 |
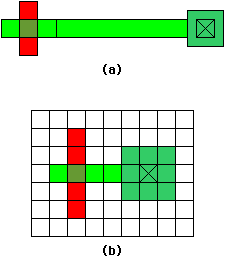
| FIGURE 5.4 Polygon operations for design-rule checking: (a) Original polygons (b) Bloated polygons (originals are dotted) (c) Intersection of bloated polygons (violation). |
Figure 5.4 shows an example of using this method to detect a spacing error. The merged polygons are bloated by one-half of the minimum spacing and then anded with each other to find any overlap. Algebraically, the error polygon is derived as:
| error | = | bloat | ( | poly1, | minspace | ) | bloat | ( | poly2, | minspace | ) | |
Implementation of polygon-based design-rule checking requires the availability of intermediate layers that can hold temporary results of the algebra. When run incrementally to check new polygons, these operations can run without consuming excessive time or space. However, when an entire layout is checked at once, the intermediate layers can use a large amount of storage. In addition, polygon intersection can be very time consuming when all the polygons on a layer must be checked. For this reason, many techniques exist to speed the polygon comparison process.
Bounding-box values, stored with each polygon, can be used to
eliminate quickly those polygons that should not be considered.
However, even with this information it is necessary to compare all polygons
when searching for overlap.
A better method is one that breaks the layout into a grid of polygon
subsets [Crawford; Bentley, Haken and Hon].
Each polygon need be checked against only those in its immediate grid area.
As the number of grid lines increases, the number of polygons in a
grid subset decreases and the neighborhood of a polygon becomes faster
to check.
However, polygons that cross or are near grid lines must be included
in multiple grid subsets and this redundancy becomes more expensive as
the grid becomes finer.
At the limit, the grid lines are as fine as the minimum unit of design
and the data structure becomes a bit-map of the layout.
Since the extremes of this grid scheme are not effective, it is important
to find a good value of grid spacing that optimizes time and space.
Bentley, Haken, and Hon found that for designs that have n boxes,
a grid size of
![]() n ×
n ×
![]() n is best.
n is best.
| Another method of comparing neighboring polygons sorts the edges along one axis. If, for example, all polygons are sorted by their left edge, then the layout can be effectively scanned from left to right. This is done by moving a vertical scan line horizontally across the layout and maintaining a working set of polygons that intersect this scan line (see the shaded polygons in Fig. 5.5). As the scan line advances, new polygons are added to the working set and old ones are removed. If the polygons are presorted, they can be efficiently paged from disk and large designs can be represented with a small amount of memory. When the set is initially formed, all pairs of polygons must be compared, but as the scan line advances, each new polygon need be compared only to the others already in the set. To enhance efficiency further, the scan line can be made to advance a variable distance, always stopping at polygon edges. This is possible because no polygons will be added to or deleted from the working set if the scan line moves to a position that does not border a polygon. The sorted list of polygons can act as a source of coordinates for the advancement of the scan line. |
|
Another approach to polygonal design-rule checking is to simplify the geometry so that the distance calculations can be quickly done. For example, if the corners of all polygons are rounded, then non-Manhattan distances are easier to calculate. Even simpler is the reduction of a design to a collection of variable-width lines [Piscatelli and Tingleff]. This notion is especially useful for printed-circuit board design-rule checking since the boards have only wires and no components. A three-part algorithm determines first whether two lines are at all close, then whether they intersect, and finally whether lines are too close but not connected. In this algorithm, a line from (x0, y0) to (x1, y1) is represented parametrically as:
One observation that is often made about design-rule checking is that its process is similar to that of node extraction [Losleben and Thompson]. For example, the three-part algorithm can also do node extraction by following intersections of wires. When wires are too close, they are considered to connect. If two different signals of a layout end up connected, then an electrical-rule violation has occurred. On printed-circuit boards, complete node extraction is done by using this information in combination with the interlayer drill holes to propagate network paths to all layers [Kaplan].
|
An alternative to using polygon algebra is the raster method of design-rule
checking [Baker and Terman].
This is similar to the raster method of node extraction, in which a small
window is used to examine the design uniformly.
Every position of the window examines a different configuration
and matches it against a set of error templates.
If, for example, metal wires must be 3 |
|
There are a number of problems with the raster method of design-rule
checking.
The time spent comparing error templates with windows can be excessive,
especially if the templates are numerous and the window is large.
It is only by using simplified design-rules, in which the largest spacing
is 3![]() and all distances are integers, that a window as small and
manageable as 4 × 4 can be used.
With a window this small, all templates for one layer can be referenced
directly through a table that is 24×4 = 65,534
entries long [Baker and Terman].
Another problem with this raster-based analysis is that it
suffers from tunnel vision and
can miss information that helps to clarify a particular configuration.
This causes extraneous errors to be reported.
For example, since the window cannot see global connectivity, it cannot
understand that two points may approach each other if they connect elsewhere.
When faced with the choice of reporting too many errors or too few,
most design-rule checkers fail on the side of inclusion and
let the designer ignore the spurious complaints.
and all distances are integers, that a window as small and
manageable as 4 × 4 can be used.
With a window this small, all templates for one layer can be referenced
directly through a table that is 24×4 = 65,534
entries long [Baker and Terman].
Another problem with this raster-based analysis is that it
suffers from tunnel vision and
can miss information that helps to clarify a particular configuration.
This causes extraneous errors to be reported.
For example, since the window cannot see global connectivity, it cannot
understand that two points may approach each other if they connect elsewhere.
When faced with the choice of reporting too many errors or too few,
most design-rule checkers fail on the side of inclusion and
let the designer ignore the spurious complaints.
| The advantages of raster-based design-rule checking are that it is a simple operation and that it takes little space. The simplicity of this method has led to hardware implementations [Seiler]. The saving of space is based on the fact that raster data can be produced from polygons in scan-line order and then the data can be destroyed when the window has passed [Wilmore]. Thus, for a 4 x 4 window, only four scan lines need to be kept in memory. In addition, the representation can be further compacted by having the unit squares of the raster be of variable size according to the spacing of polygon vertices in the original layout [Dobes and Byrd]. These essential bit-maps (see Fig. 5.7) have more complex templates with rules for surrounding spacing but they save much memory because they represent the layout in a virtual grid style. |
|
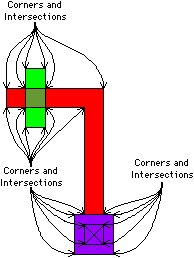
| The polygon approach to design-rule checking takes too much space and the raster approach has too narrow a view to be effective, but there are other ways to check geometric spacing. The Lyra design-rule checker [Arnold and Ousterhout] checks the corners and intersections of polygons against arbitrary spacing rules (see Fig. 5.8). Since checking is done only where the geometry changes, the scope of a corner is equivalent to a 2 × 2 window on an essential bit-map. However, the spacing rules that are applied to each corner can examine arbitrarily large areas that would exceed a fixed-window capability, even when using essential bit maps. |
|
|
Figure 5.9 illustrates the Lyra design rules.
Once again, the rule is that no two metal wires may be closer than 3 |
|
When applying the templates, Lyra uses special code for efficiency. Lyra uses a tabular approach in which the corner configuration is indexed into a set of dispatch tables to determine which rules apply. In addition, all rotations of the template must be checked. A simple compiler produces the templates and rules from higher-level design-rule descriptions and automatically handles different template orientations. Although Lyra uses only Manhattan geometry, it would be feasible to extend this corner approach to non-Manhattan checking by including corner-angle ranges in the template.
If design-rule checking can be done with syntactic methods, then it is
not unreasonable to apply traditional syntax-checking techniques
used in compilers.
In particular, it is possible to do design-rule checking by following
state diagrams [Eustace and Mukhopadhyay].
Since compiler-state machines work on one-dimensional data, a
design-rule checking-state machine must be modified to have two entries for
state selection so that it can look in two orthogonal directions.
Thus, for a 13-state machine, there are 132 table entries to account
for all combinations of the states in two orthogonal directions.
Figure 5.10 shows a state table for the 3![]() metal-spacing rule.
Starting in state 0, the vertical (V) and horizontal (H) neighbor
states are examined along with the presence or absence of metal.
This determines the state for the current point and flags errors (E).
metal-spacing rule.
Starting in state 0, the vertical (V) and horizontal (H) neighbor
states are examined along with the presence or absence of metal.
This determines the state for the current point and flags errors (E).
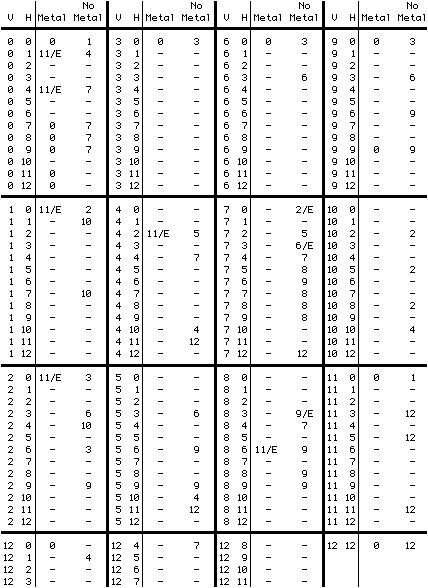 |
| FIGURE 5.10 State-based design-rule checking. |
Producing state diagrams for design rules can become very complex. What is needed is a compiler that produces the state tables from higher-level-rule specifications. With such a facility, design-rule checking can be done in such a simple manner that it can be easily implemented in hardware. Augmentation of the state table to include memory would reduce table size with only a modest increase in state-machine complexity. This totally state-oriented approach is a generalization of the Lyra technique in that both methods use rules for handling layer-change points. However, with enough states, the state-oriented method can also handle global information between change points.
Hierarchy is an important factor in simplifying design and is therefore useful in simplifying design analysis. Besides speeding the process, the use of hierarchy can make error messages more informative by retaining knowledge of the circuit structure. If two instances of a cell are created in similar environments, then it should not be necessary to check the contents of both of them. Hierarchical design-rule checking has been used to eliminate those polygons that are redundant in a layout [Whitney]. A precheck filter removes all but one instance of a cell and leaves only those combinations of cell intersections that are unique. This same technique has been used in node extraction by reducing a cell to its external connection geometry and examining the contents only once to assign network labels [Chao, Huang, and Yam]. The extracted network can be hierarchically structured, which may be useful to other tools [Newell and Fitzpatrick]. In fact, many analysis tasks can be improved by hierarchically examining a circuit so that only one instance of a cell and its overlap is considered [Hon].
Care must be taken to ensure that instances of a cell eliminated from the check have identical environments of geometry at higher levels of the hierarchy. For example, a piece of layout placed arbitrarily across a cell may have varying effects on the design rules of identical subcells farther down the hierarchy. In regular and well-composed hierarchies, a hierarchical design-rule checking filter eliminates much of the layout and vastly speeds checking. Restricted design styles, such as those that do not allow cell overlap, will make hierarchical checking most efficient [Scheffer]. However, in poorly-composed hierarchies, the filter can spend more time looking for unique instance configurations than would be spent in a nonhierarchical check.
A simpler use of hierarchy in speeding design-rule checking is the use of cell location to restrict the search for a polygon's neighborhood [Johnson; Shand]. Since cell instances provide bounding boxes for their contents, this information can be used to eliminate entire cells and their subcells from consideration. Where cells overlap, checking recurses through their contents, using boundary information to find neighboring polygons quickly. Shand also uses this scheme for node extraction. Thus it can be seen that hierarchy, in combination with good search methods, speeds design-rule checking and other analysis tasks.
|
Previous |  |
Table of Contents | Next | |
 |
Electric Editor, Inc. |