|
|
|
 출처: 월간 Semiconductor Network / 1999년 6월호 / p.82~p.89 출처: 월간 Semiconductor Network / 1999년 6월호 / p.82~p.89
|
|
Author: 박해강 (XILINX Korea 기술부장)
|
PLD는 DSP (Digital Signal Processing / 디지털 신호 처리)의 연산 기능을 위한 대안을 제공하여 보다 저렴한 시스템 비용으로 더욱 향상된 DSP 시스템 성능을 얻을 수 있도록 한다. 또한, PLD는 범용 DSP의 유연성과 ASIC의 속도/집적도/저렴한 가격을 겸비하고 있다. 어떤 애플리케이션에서는 PLD가 DSP 프로세서를 완전히 대체하고 있으며, 또 어떤 애플리케이션에서는 PLD가 DSP 프로세서와 함께 사용돼 연산 기능을 담당하므로써 DSP 프로세서가 다른 기능을 할 수 있도록 한다.
DSP는 전자 산업에서 가장 빠른 속도로 성장하고 있는 분야 가운데 하나이며, 다음과 같은 다양한 애플리케이션에서 사용되고 있다.
- 통신
- 데이터 통신
- 무선 통신
- 이미지 향상 및 처리
- 자료 수집
- 원격 감지
- 레이더
- 비디오 (화상) 처리
- 방송 (HDTV)
- 음성 합성 및 인식
시중에 나와 있는 많은 고성능 DSP 프로세서들이 모든 DSP 애플리케이션에 적합한 것은 아니다. 이들의 범용 아키텍처는 DSP 프로세서에 유연성을 제공하지만, 모든 시스템에 적용될 수 있을 만큼 빠르거나 비용 효율적이지 않을 수도 있다. 여기서는 전통적인 범용 DSP 프로세서에 대한 대안을 소개한다. FPGA (Field Programmable Gate Array)나 CPLD (Complex Programmable Logic Device)는 기존의 DSP와 동일한 유연성을 갖고 있으면서 이를 능가하는 성능 향상을 제공할 수 있다.
DSP란?
PLD가 어떻게 다양한 DSP 기능을 제공하는지 설명하기 전에 먼저 DSP에 대한 정의가 필요하다. “DSP”는 실시간으로 행해지는 연속적인 수리적 처리에 광범위하게 적용되며 다음과 같은 기능을 포함하고 있다.
- 디지털 필터링
- FIR (Finite Impulse Response)
- IIR (Infinite Impulse Response)
- Viterbi 디코더
- Convolution
- Correlation
- FFT (Fast Fourier Transforms)
대부분의 이런 기능들은 들어오는 데이터를 다양한 내부 피드백 메커니즘을 가지고 곱하거나 더해 원하는 수리적 함수를 실행한다. 이 함수는 일반적으로 Multiply / Accumulate로 불린다.
성능 향상을 위해 대부분의 범용 DSP 프로세서는 단일 클럭 사이클(또는 그 이하)에서 Multiply / Accumulate 함수를 실행한다. 이 함수를 실행하는 하드웨어는 MAC (Multiply / Accumulator)로 불린다. 대부분의 DSP 프로세서들은 fixed-point MAC를 갖고 있으나 일부 DSP 프로세서들은 고기능의 floating-point MAC를 갖고 있기도 하다.
전통적 접근법
전통적으로 DSP 기능은 범용 DSP 프로세서에, 또는 ASIC 기술을 이용해 구현되었다.
ASIC이나 게이트 어레이 기술은 일반적으로 애플리케이션이 현재의 DSP 성능 이상을 요구하거나, 또는 예상되는 시스템 볼륨이 커서 semi-custom 솔루션을 필요로 하는 경우 이용된다.
그러나 PLD은 DSP와 ASIC 기술의 한계를 극복하고 장점만을 결합한 제3의 솔루션을 제공한다.
PLD의 잠재력
최고의 DSP와 ASIC 기술 겸비
(1) 향상된 유연성
범용 DSP와 마찬가지로 FPGA와 CPLD는 프로그래밍과 변경이 가능하다. 디자이너는 ASIC에서 요구되는 추가 비용과 긴 리드 타임 없이 신속하게 변경할 수 있다. DSP와 마찬가지로 FPGA는 최소한의 볼륨 조건이 없지만 ASIC은 이 조건이 있다.
성능이 중요한 요소일 때는 대부분의 디자이너들이 ASIC 기술에 의존한다. ASIC 기술은 타깃 애플리케이션용으로 최적화된 맞춤 아키텍처를 제공한다.
예를 들어, 디지털 필터링은 대개 수많은 MAC 사이클 (각 필터 탭을 위해서는 하나의 MAC 사이클이 필요)을 요구한다. 기존의 DSP는 단일 MAC를 갖고 있기 때문에 각 필터 탭은 순차적으로 실행되어야 한다. 필터 알고리즘을 ASIC으로 구현하면 수많은 MAC를 가질 수 있기 때문에 모든 탭들이 병렬 처리될 수 있다.
이와 마찬가지로 FPGA는 어떤 구체적 DSP 기능에 적용시킬 수 있는 유연한 아키텍처를 가지고 있다. 또한, FPGA는 애플리케이션이 요구하는 인터페이스 회로와 다수의 MAC, 또는 알고리즘을 단일 디바이스에 포함시키기에 충분한 용량을 갖고 있다. DSP 프로세서와 비교되는 단일 칩 솔루션인 셈이다.
(2) FPGA로 향상된 DSP 성능
DSP 아키텍처는 시스템 성능에 직접적인 영향을 미친다. 대부분의 DSP 기능은 Multiply / Accumulate에 기반을 두고 있기 때문에 MAC의 성능이 매우 중요하다.
거의 모든 프로세서는 Multiply / Accumulate을 실행할 수 있기 때문에 DSP 알고리즘을 실행할 수 있다. 범용 DSP와 마이크로프로세서간의 유일한 차이는 그들이 이 기능을 얼마나 잘 실행하는가 하는 것이다.
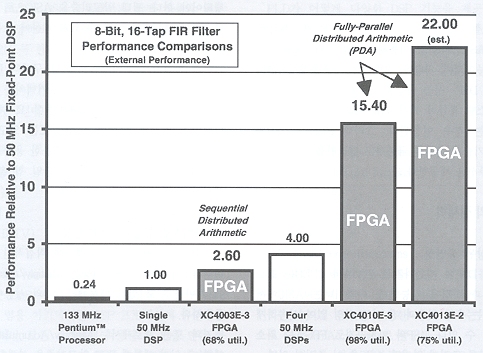
(그림1) 50 MHz fixed-point DSP 프로세서를 기준으로 하여 다양하게 구현된 8비트, 16탭 FIR 필터의 상대적 성능. FPGA가 최고 22배 더 빠르다.
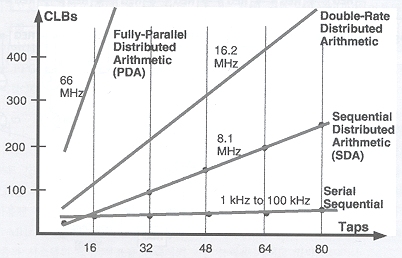
(그림2) 각기 다른 DA(Distributed Arithmetic) FIR 필터 구현 성능과 XC4000E FPGA 로직 블록(CLB)에서의 상대적 실리콘 효율성
예를 들어, 대부분의 DSP 프로세서는 하나의 사이클만 필요로 하는 반면, 펜티엄™ 프로세서는 단일 Multiply / Accumulate연산을 실행하는데 11 클럭 사이클을 필요로 한다. 50 MHz fixed-point DSP는 불과 20 ns만에 Multiply / Accumulate 사이클을 실행하는 반면, 133 MHz 펜티엄 프로세서는 동일한 기능을 실행하는데 1.3 ㎲를 필요로 한다. 그 결과, 133 MHz 펜티엄 프로세서는 그림1에서 보여지는 바와 같이 필터 기능용 50 MHz DSP의 24%에 해당하는 DSP 프로세싱 능력밖에 갖고 있지 못하다.
디지털 필터의 각 탭은 하나의 MAC 사이클을 필요로 한다. 예를 들어, 16탭 필터 하나는 16 MAC 사이클을 필요로 한다. 대부분의 DSP는 하나의MAC 만 갖고 있기 때문에 각 탭은 순차적으로 처리되며, 따라서 전체적인 시스템 성능이 떨어진다.
좀더 강력한 (따라서 좀더 고가인) DSP 가운데 일부는 다수의 MAC을 가지고 있다. 이런 DSP는 하나의 클럭 사이클에서 다수의 MAC를 실행한다. 공유 고속 메모리를 가진 다수의 단일-MAC DSP를 이용해도 동일한 결과를 얻을 수 있다. 모든 경우, 부가적인 성능의 향상을 위해서는 더 높은 부품 비용 및 더 넓은 보드 공간이 요구된다.
FPGA는 특정 애플리케이션에서 훨씬 강력한 아키텍처를 제공한다. FPGA의 로직은 유연하고 정해진 형식이 없기 때문에 DSP 기능은 FPGA상에서 제공되는 자원에 직접 매핑될 수 있다.
FPGA 구현은 대부분의 DSP 보다 더 빠를 뿐 아니라 시스템 집적도와 성능간의 관계에 따른 옵션도 제공한다. 그림1은 50 MHz fixed-point DSP 프로세서의 성능을 기준으로 다양하게 구현된8비트, 16탭 FIR 필터의 상대적 성능을 보여준다.
이 그림에서 볼 수 있듯이 가장 효율적인 FPGA 구현은 XCS30-3 FPGA의 68%, 즉, 약 1,500 게이트를 이용하고 있다[1]. 이 구현은 단일 50 MHz DSP 보다 2.6배 우수한 성능을 보이고 있다. 이러한 효율성의 열쇠는 SDA (Sequential Distributed Arithmetic) 알고리즘이다[2, 3]. 이 알고리즘은 XCS30 아키텍처의 특징을 이용한다. Multiply 함수는 FPGA의 펑션 제너레이터에 매핑되며, adder와 accumulator는 XCS30 고속 캐리 로직을 이용하고, 시리얼 시프트 레지스터는 효율적인 온 칩 램에 구축된다[4].
가장 우수한 성능의 FPGA 구현은 XCS30-4 FPGA의 약 75%, 즉 약 9,750 게이트를 이용한다. 이 고성능 구현은 공간 효율 버전 보다 약 7배 더 크지만 이 애플리케이션에서는 50 MHz DSP 보다 22배 더 빠르다. 이 구현은 PDA (Parallel Distributed Arithmetic) 알고리즘을 이용하고 있다[2, 3]. 애플리케이션이 파이프라이닝에 의해 초래된 엑스트라 데이터 레이턴시를 허용할 수 있다면 더 우수한 성능도 가능하다. 동일 칩에서 필터가 다른 로직과 통합되어I/O 딜레이를 피해가게 되면 성능은 더욱 향상될 것이다.
다양한 대안 FPGA 구현도 가능하다. 다양한 알고리즘을 위한 집적도와 성능간의 관계는 그림2에 나타나 있다. 각 구현은 타깃 애플리케이션의 속도, 집적도, 비용 요건에 맞춰져 있다. 직렬 순차 (serial sequential) 알고리즘이 가장 효율적이지만 가장 느리다. PDA는 가장 빠르지만 또 가장 많은 로직을 이용한다. SDA는 시스템 조건에 따라 다르지만 속도와 집적도가 잘 조화를 이루고 있다.
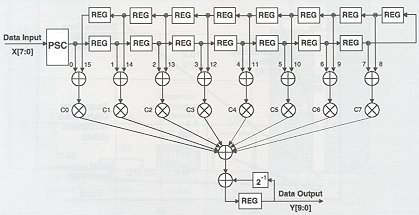
(그림3) DSP 프로세서 속도를 떨어뜨리는 병렬 연산과 피드백 경로를 보여주는 16탭 FIR 필터의 데이터 플로우 다이어그램. FPGA는 클럭 사이클당 다수의 연산을 실행, 더 우수한 성능을 제공한다.
(3) PLD을 이용한 DSP 비용 절감
DSP 프로세서를 대체하는 FPGA
일부 애플리케이션에서는 단일 FPGA 또는 CPLD가 전용 DSP를 완전히 대체하고 있다. 이런 애플리케이션은 대개 데이터 샘플 속도가 100 kHz부터70 MHz까지인 임베디드 프로세싱 또는 필터링 기능이다.
임베디드 필터링 애플리케이션에서는 DSP 기능이 변하지 않으며, 따라서 범용 DSP가 가진 부가적 유연성은 별다른 혜택도 없이 비용 부담만 늘리게 된다.
1 kHz-100 kHz 범위에서는 DSP 기능 (그리고 모든 다른 시스템 로직)이 저가의 단일FPGA에 모두 들어간다. 이 접근법은 그림2에서처럼 실리콘 효율성 (silicon-efficient)이 높지만 성능이 떨어지는 직렬 순차 알고리즘을 이용한다.
(4) FPGA에 의한 범용 DSP 성능 향상
FPGA와 CPLD는 범용 DSP 프로세서를 완전히 대체하지는 않을 것이다. 현세대의 PLD은 전체 시장 중에서 fixed-point DSP가 차지하고 있는 영역을 대상으로 하고 있다. floating-point 성능 분야에서는 여전히 범용 DSP가 주도하고 있다. 또한 범용 DSP 프로세서들은 친숙한 소프트웨어 방식을 이용하고 있다. 디자이너는 ‘C’ 같은 프로그래밍 언어를 이용해 DSP 알고리즘을 구현하고 특정 DSP 프로세서용 코드를 컴파일한다.
많은 애플리케이션에서, 초고가의 고속 DSP 프로세서가 코드 일부분의 피크 성능을 처리하는데 사용되고 있다. 전형적인 DSP 알고리즘은 그림3의 16탭 FIR 필터를 위한 데이터 플로우 다이어그램에서 볼 수 있듯이 많은 반복 피드백 루프와 병렬 구조를 포함하고 있다. 그런 알고리즘을 위한 소프트웨어 코드는 범용 DSP 아키텍처에서 효율적으로 구현되지 않는다. 일반적으로 DSP 코드의 약 20-40%가 DSP의 프로세싱 파워의 60-80%를 이용하고 있다.
DSP 성능을 향상시키기 위해 많이 사용되는 방법 중 한가지는 다수의 DSP를 병렬로 이용하고 고속 메모리를 이용하는 것이다. 예를 들어, 그림1에서와 같이 4-DSP 솔루션은 이론적으로 단일 DSP 솔루션 보다 4배의 성능을 제공한다. 그러나 비용은 4배 이상 비싸다. 이런 멀티칩 DSP 디자인은 일반적으로 더 넓은 보드 공간과 고성능 메모리를 요구하며, 따라서 비용도 추가된다.
이 방법 대신 이런 애플리케이션을 위한 최고의 솔루션이 될 수 있는 것은 아마 FPGA 코프로세서를 갖춘 마이크로컨트롤러, 마이크로프로세서, 또는 DSP 프로세서일 것이다. 범용 DSP 프로세서는 시스템 제어 및 데이터 이동 기능을 처리한다. FPGA는 피크 프로세싱 기능을 처리해주는 맞춤(custom-tailored) DSP 코프로세서를 제공한다. 더 자세한 내용은 사례 연구: Viterbi 디코더를 참고하기 바란다.
DSP 알고리즘을 분석하면 DSP 프로세싱 파워를 소모하는 모든 병렬 구조와 반복 루프가 드러난다. FPGA에 이런 기능을 포함시키면 전체 성능이 향상된다.
FPGA 기반의 DSP 가속기 개념은 마이크로프로세서와 함께 작동하는 floating-point 코프로세서와 비슷하다.
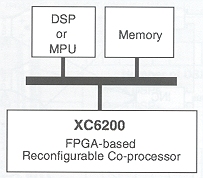
(그림4) 고속 프로세서에 연결된 XC6200 FPGA 응용
(5) ASIC을 대체하는 FPGA
FPGA는 DSP 시스템에서 ASIC을 대체할 수도 있다. 디자이너가 과거에 ASIC을 선택한 이유는 2가지였다. 범용 DSP의 능력을 능가하는 DSP 프로세싱 파워가 필요하거나 semi-custom 솔루션을 필요로 할 만큼 대량 생산이 가능한 시스템인 경우였다.
ASIC과 마찬가지로 FPGA와 CPLD는 범용 DSP 보다 더 우수한 성능을 제공할 수 있다. 고집적 FPGA가 제공되기 전에는 DSP 성능을 필요로 하되 대량 시스템 출시가 어려웠던 업체들은 ASIC 기술을 사용할 수밖에 없었다. 최소 물량 조건과 오랜 리드 타임, NRE (non-recurring engineering changes), 그리고 ASIC의 위험 요소들은 소량 생산 프로젝트에 맞지 않았다. FPGA는 ASIC의 성능과 아키텍처상의 유연성을 제공하되, 사용자가 프로그래밍 할 수 있으므로 개발비가 저렴하다.
일반적인 생각과는 달리 FPGA는 대량 생산 디자인을 위한 솔루션도 제공한다. 자일링스의 Spartan/XL series디바이스는 DSP 솔루션에 적합한 아키텍처 를 가지고 있으며 대량 생산에 적용될 수 있도록 저렴한 가격으로 공급되고 있다. 게다가, 대량 생산 사용자를 위해 추가 옵션을 제공하고 있다. 자일링스 하드와이어(HardWire™) 게이트 어레이는 상응하는 자일링스 FPGA와 100% 핀 및 기능 호환이 가능하며, 부품비를 50-80%까지 줄여준다.
사례 연구: Viterbi 디코더
한 업체가 DSP 기반의 통신 시스템을 개발했다. 핵심 DSP 알고리즘 가운데 하나가 소음 방지 회로의 일환으로 사용된 Viterbi 디코더였다[6]. 이 디자인은 상용화된 66 MHz 범용 DSP 프로세서 2개를 사용했다. 알고리즘과 시스템의 성능 목표를 만족시키기 위해 고속 S램 메모리도 필요했다.
Viterbi 디코더는 어떠한 multiply 연산도 필요로 하지 않지만 수학적 처리 때문에 DSP 알고리즘으로 간주될 수 있다. 그림5에 잘 나타나 있듯이 이 알고리즘은 17개의 계산 클럭 사이클, 그리고 DSP의 외부 S램 메모리 대기 상태를 위한 7개의 추가 클럭 사이클이 필요했다. 24비트 데이터 워드 7개(2의 보수)는 공통의 33 MHz I/O 버스상에서 함께 멀티플렉스되었다. 그 결과, Viterbi 디코더 알고리즘은 360 ns 처리 시간 (사이클당 15 ns로 24 사이클)을 필요로 했고, 복합 DSP 총 처리 시간의 약 80%를 소모했다.
이 DSP 기반 디자인에는 2가지 제한 요소가 있다. 첫째, 외부 S램 타이밍이 여분의 15 ns 대기 상태를 필요로 하기 때문에, 데이터 버스는 각 트랜잭션 당30ns로 제한되었다. 둘째, 각각의 Add / Subtract와 Multiplex 단계가 DSP에서 순차적으로 실행되어야 한다. Add / Subtract 단계는 각각 여러 차례의 명령으로 4차례의 별도 연산을 필요로 했다.
이 알고리즘은 FPGA용으로 잘 맞는다. 병렬 데이터 경로를 처리하는 FPGA의 능력은 1단계에서 ADD / SUB 블록 4개의 병렬 구조를, 또 2단계에서 SUB 블록 2개의 병렬 구조를 처리한다. 2개의 MUX 블록은 아무런 추가 클럭 사이클 없이 필요할 때까지 인풋 데이터를 레지스터하거나 지연하는 능력을 가지고 있다.
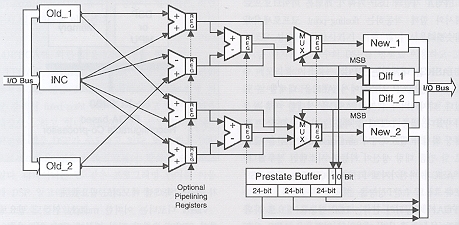
(그림5) Viterbi 디코더 블록 다이어그램. FPGA는 다수의 Add / Subtract기능을 병렬로 구현, 더 우수한 성능을 제공한다.
디자인 변환은 그림6에서처럼 더 빠른 성능을 가져다 준다. FPGA 기반의 Viterbi 디코더 사이클 기간은 135ns로서 듀얼 DSP 디자인의 360 ns 보다 62% 빨라졌다. I/O 데이터 버스는 DSP 프로세서가 지원하는 완전한 66 MHz대역폭을 지원한다. 원래 스루풋의 2배 수준이다. 표1에서 볼 수 있듯이 FPGA 기반 구현은 프로그래머블 DSP 한 개와 S램 칩 3개를 대체해 성능면에서는 더 우수해지고 시스템 복잡성은 상당히 줄어들었다. Viterbi 디코더는 XCS30-3 FPGA의 44%를 사용했다. 나머지 공간은 다른 시스템 로직으로 채워졌다.

(그림6) 두가지 Viterbi 디코더 구현의 성능. DSP + FPGA 솔루션이 더 빠르다.
| (표1) FPGA로 줄어든 부품 수
|
DSP 만 사용했을 때 |
DSP + FPGA |
디바이스 8개 |
디바이스 4개 |
66 MHz DSP 2개
15 ns S램 6개
시스템 로직 |
66 MHz DSP 1개
XCS30-3 FPGA(44%)
15 ns S램 3개 |
이 디자인은 또한 원래의 33 MHz I/O 버스 성능으로 구현될 수 있다. 이러한 구현은 이 디자인의 대칭성(symmetrical nature)을 이용, 필요한 CLB를 최소화 해준다. Old_1과 Old_2 값이 2단계 SUB 블록에서 사소한 차이만 있을 뿐 동일한 경로를 따른다는 점을 눈여겨 보길 바란다. 이러한 구현에서는 I/O 데이터 버스상의 데이터가 특정 순서에 따라 쓰고 읽혀져야 한다.
정리: DSP를 위해 FPGA 이용하기
앞서 소개한 사례 연구는 FPGA가 DSP 성능을 어떻게 향상시키고, 어떻게 전체 시스템 비용을 줄여주는지 보여주는 한 가지 사례일 뿐이다.
(1) 적절한 기능 찾기
DSP 애플리케이션의 성능을 향상시키기 위해 FPGA를 이용하려면
- 알고리즘에서 병렬 데이터 경로를 식별해낸다. DSP는 이들을 순차적으로 실행해야 하지만 FPGA는 이런 기능을 병렬 구현할 수 있다.
- 범용 DSP에서 실행될 때 다수의 클럭 사이클을 요하는 연산을 찾아낸다. 이때도 FPGA의 병렬 구현을 이용할 수 있다.
(2) FPGA가 가장 적합한 DSP 기능
이밖에 다음과 같은 요소를 포함하고 있는 DSP 애플리케이션들이 FPGA 기술의 혜택을 얻을 수 있다.
- 고속 샘플 속도 ? FPGA 기반의 DSP 시스템은 한 개 이상의 범용 DSP 프로세서보다 더 우수한 성능을 제공한다(그림7).
- 저속 샘플 속도 ? 1 kHz-100 kHz의 데이터 속도에서, DSP 기능은 아주 효율적인 직렬 순차 알고리즘을 이용해 저가 FPGA에서 다른 시스템 로직과 쉽게 통합될 수 있다.
- 짧은 워드 길이 ? FGPA 기반의 DSP 디자인은 공간 효율적인 SDA 알고리즘을 이용할 경우 워드 폭이 줄어들기 때문에 더 빨리 실행된다.
- 많은 필터 탭들 ? 필터 탭의 수는 공간 효율적인 SDA 알고리즘을 이용할 경우 FPGA 기반의 DSP 디자인에 거의 영향을 미치지 않는다.
- 단일 칩 솔루션 요구 ? DSP 기능과 모든 시스템 로직을 단일 FPGA에 통합한다.
- 고속 상관 관계 ? 자일링스 FPGA의 룩업 테이블 아키텍처는 상관 관계 수립을 위한 빠르고 효율적인 방법을 제공한다.
- 저가 마이그레이션 경로 ? 자일링스 하드와이어 게이트 어레이는 대량, 저가 생산 솔루션으로 옮겨가기 위한 위험성 적고, 100% 핀 및 기능 호환이 가능한 마이그레이션 경로를 제공한다. 어떠한 시뮬레이션이나 테스트 벡터, 리엔지니어링도 필요하지 않다.
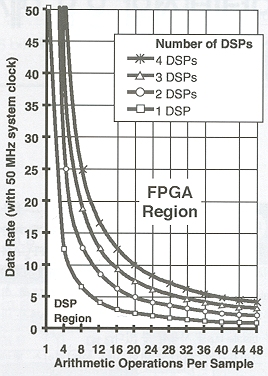
(그림7) FPGA 기반의 DSP vs. 한 개 이상의 DSP 프로세서의 성능을 보여주는 그래프. 흐린 색으로 표시된 부분은 어느 부분에서 FPGA가 더 우수한 솔루션인지를 나타내준다.
(1999.6.28)
|